Daten nutzbar machen
Szenarien und Werkzeuge

André Schütz
Wegtam GmbH
Wer sind wir?
Wegtam GmbH
- Spezialisierung auf Datenmanagement
- Integration, Suchthematik, Big Data, BI
- Softwareentwicklung
- Functional Programming (Scala)
- Beratung (Open Source)
Übersicht
- Wo können Daten herkommen?
- Wie erfolgt der Zugriff auf die Daten?
- Wo können Daten abgelegt werden?
- Zu welchem Zweck?
- Beispiele
- Zunahme der Komplexität
- Wahl der Technologien
Wo könnten Daten herkommen?
- Diverse Softwaresysteme (CRM, ERP, Shops, ...)
- Internet of Things (Sensordaten, Maschinendaten, ...)
- Interessante Informationen (Reports, Logs, Monitoring, ...)
- Vorverarbeitete Daten (Smart Data)
Fragestellung: Welche Daten benötige ich in welchem Umfang und in welcher Qualität?
Wie erfolgt der Zugriff auf die Daten?
- Datenbanken (meist SQL)
- Dateien
- Parsen notwendig (CSV, XML, etc.)
- Schnittstellen/APIs (Programmierung bzw. existierende Lösungen)
Fragestellung: Nutzung einer bestehenden Softwarelösung oder eigene Datenintegration?
Wo können Daten abgelegt werden?
- Relationale Datenbanksysteme (RDBMS)
- PostgreSQL, MySQL, Sqlserver, etc.
- NoSQL Datenbanksysteme
- Cassandra, MongoDB, Voldemort, etc.
- Dateien
- Komprimierte Daten, die nur gelegentlich genutzt werden
Fragestellung: Wie sollen die Daten später genutzt werden? Zugriffsgeschwindigkeit versus Struktur.

Zu welchem Zweck?
- Erschreckend oft keine klare Zielvorstellung
- Hoffnung auf "Die KI wird das schon machen."
Zu welchem Zweck?
- Klare Ziele definieren
- Auswirkungen beachten
Zu welchem Zweck?
Nicht immer ist, alles was möglich ist - auch sinnvoll!
Drei Beispiele


1.) Erfassung und Auswertung von Trackingdaten
- Daten aus verschiedenen Trackingsystemen sollen zusammengeführt und auf
Anomalien analysiert werden
- Aufdeckung von Klickbetrug
- Musterentdeckung in Bewegungsdaten (Tracking von Fahrzeugen)
1.) Erfassung und Auswertung von Trackingdaten
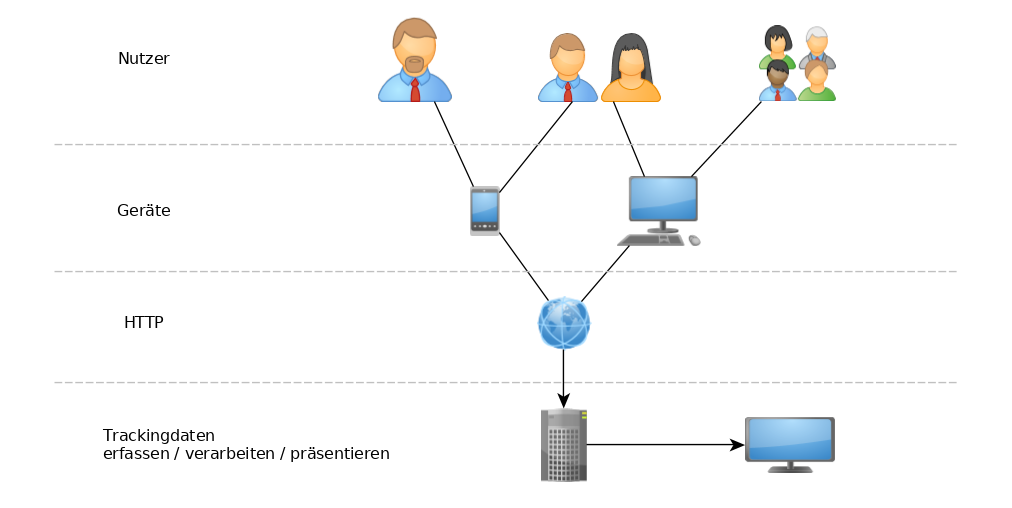
1.) Erfassung und Auswertung von Trackingdaten
- Datenquellen:
- CSV-Dateien, Datenbank eigener Software
- Verarbeitung:
- einfache Skripte (Vorverarbeitung, Bereinigung, Import)
- Datensenke:
- relationale Datenbank (z.B. PostgreSQL, MySQL oder Sqlserver)
1.) Erfassung und Auswertung von Trackingdaten
- Analysen:
- einfache Skripte und Datenbankprozeduren (stored procedures)
- Ausgaben:
- direkte Ausgaben
- generierte Dateien (Reports)
- einfache Logiken (E-Mail-Versand von Ergebnissen)
2.) Erfassung und Auswertung von Produktionsdaten
- Sensordaten von diversen Geräten (Internet of Things) sollen gesammelt und
analysiert werden
- Analyse von Messreihen für verschiedenste Zwecke (Stromverbrauch,
Gebäudetemperatur, etc.)
- Steuerung von Anlagen anhand von Berechnungsvorschriften auf den Meßreihen
2.) Erfassung und Auswertung von Produktionsdaten

2.) Erfassung und Auswertung von Produktionsdaten
- Datenquellen:
- Sensoren und Logs an diversen Geräten (IoT)
- Wie sammelt man die Daten?
- Software, die selbige abfragt (Pull)
- Geräte schreiben Daten selbst in Dateien oder gegen eine API (Push)
2.) Erfassung und Auswertung von Produktionsdaten
- Verarbeitung:
- Softwarelösung (verschiedene Möglichkeiten)
- Daten selbst einsammeln, vorverarbeiten und abspeichern (Custom)
- Dienst, der abgelegte Dateien verarbeitet und speichert (SaaS)
- Dienst, der eine Schnittstelle anbietet (z.B. REST) und die Daten dann abspeichert
2.) Erfassung und Auswertung von Produktionsdaten
- Datensenke:
- NoSQL-Datenbank (z.B. Cassandra) für Zeitreihen und Meßdaten
- Analysen:
- Analysesoftware (z.B. Jupyter, Zeppelin)
- eigene Programme (z.B. via Akka-Stream, Flink, Spark)
- Analyseausgaben:
- HTML-Browser (z.B. Jupyter, Zeppelin)
- generierte Dateien (Reports)
- komplexere Logiken (Anlagensteuerung)

3.) Erfassung und Auswertung von Labordaten und medizinischen Daten
- Daten aus Laboren mit Patienten- und Befunddaten kombinieren
- Erforschung unbekannter Zusammenhänge in Krankheitsbildern
- Entdeckung von neuen Heilmethoden
3.) Erfassung und Auswertung von Labordaten und medizinischen Daten
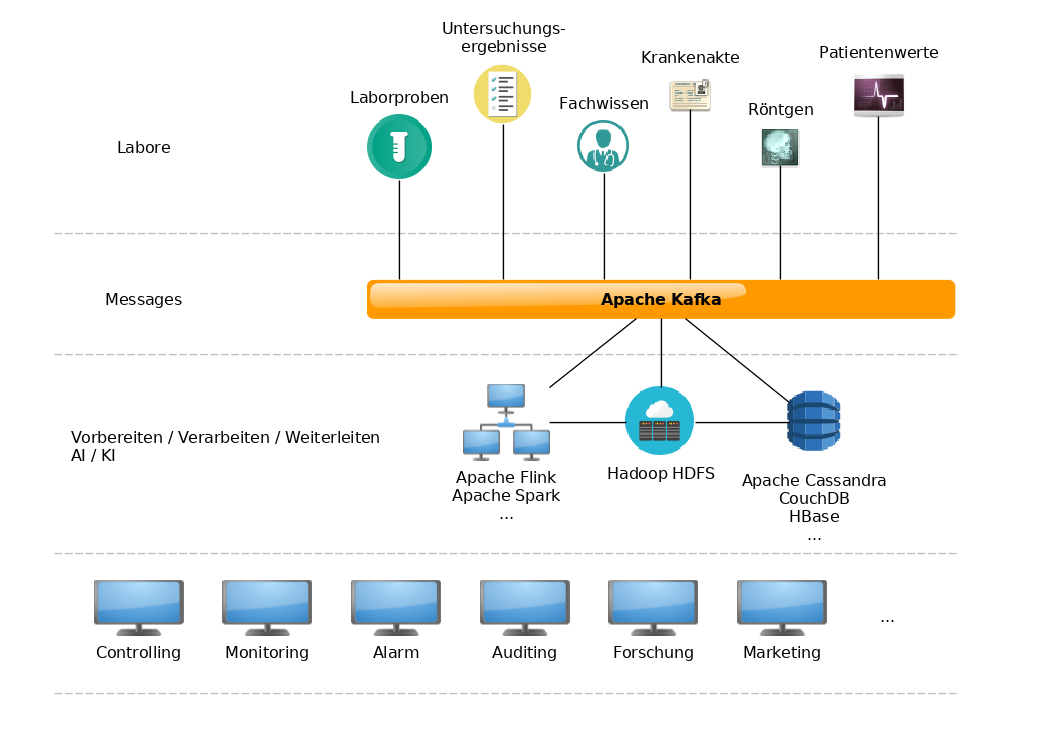
3.) Erfassung und Auswertung von Labordaten und medizinischen Daten
- Datenquellen:
- Software für Laborgeräte (meist Dateien, ggf. Datenbanken)
- medizinische Software (Patientendaten, Genetikdatenbanken, etc.)
- Verarbeitung:
- Nutzung einer zentralen Pipeline (Kafka)
- Anbindung diverser Datenquellen über Kafka-Connect
- Anbindung weiterer Datenquellen über eigene Lösungen via Flink oder Spark
- Weiterverarbeitung der Daten durch Flink oder Spark
- => Reduzierung der zu speichernden Datenmenge
3.) Erfassung und Auswertung von Labordaten und medizinischen Daten
- Datensenke:
- NoSQL-Datenbank (Cassandra)
- Analysen:
- Analysesoftware (z.B. Jupyter, Zeppelin)
- Programme für Flink/Spark, die mit Analysesoftware integriert sind
- Analyseausgaben:
- HTML-Browser (z.B. Jupyter, Zeppelin)
- generierte Dateien (Reports)
- Events/Messages über Kafka (Auslösen von Logiken)
Was haben wir hier eigentlich?

Was haben wir hier eigentlich?
- komplizierte bis komplexe Systeme
- Umgebungen, die Menschen, Maschinen, Algorithmen, Konzepte und Modelle
beinhalten
- Unsicherheiten gehören dazu
- Konsequenzen und Risiken verteilter Systeme
- Netzwerkprobleme (Verlust von Nachrichten)
- Speicherengpässe
Selbst relativ einfache Komponenten können zu höchst komplexen Systemen
führen.
Verkettungen und resultierende Kaskaden sollten nicht unterschätzt
werden.

Was haben wir hier eigentlich?
- Umgang mit Daten
- Fachwissen notwendig (Domänenexperten)
- technisches Wissen notwendig
- Statistik!!!
- weitere Zunahme der Komplexität
- Datenqualität
- Verarbeitungsregeln
- Monitoring (Systemüberwachung)

Wie wählt man Technologien und Werkzeuge?
- Nicht nur den Vertriebsbroschüren vertrauen!
- Es ist niemals so einfach
- Das eigene Problem bzw. Vorhaben richtig verstehen
- Welche Fähigkeiten werden benötigt?
- Anforderungen an die notwendige Infrastruktur beachten!

Wie wählt man Technologien und Werkzeuge?
- Systeme ausprobieren!
- Kleine Tests fahren, Prototypen implementieren
- Selbst bei Misserfolg => Erkenntnisgewinn
- Erkennen von versteckten Kosten
- Diskrepanz zwischen Dokumentation und "Realität"
Nützliche Literatur
- Designing Data-Intensive Applications - Martin Kleppmann
- Cassandra: The Definitive Guide - Jeff Carpenter, Eben Hewitt
- Kafka: The Definitive Guide - Neha Narkhede, Gwen Shapira, Todd Palino
- Reactive Design Patterns - Roland Kuhn, Brian Hanafee, Jamie Allen
Vielen Dank!

Gibt es Fragen?